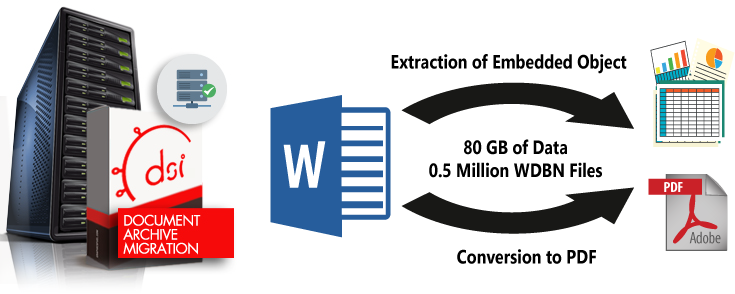
Data Strategies Interchange today is pleased to announce the successful completion of Word to PDF Bulk Conversion and Embedded Object Extraction for a major Life Insurance company.
The client had around half a Million .WDBN (Word Binary files – Word 3/4/5 Created on Macintosh) along with Old Microsoft Word files (.DOC) and New Word Files (.DOCX) with total size of 80GB ranging from the year 1993 to 2019. For portability and accessibility, client decided to convert these files to PDF.
DSI was able to execute this project in a month with following steps:
A major challenge that DSI was successfully able to handle during the Word to PDF Bulk Conversion was to identify the various versions of Microsoft Word files and to handle conversion to PDF and extraction of Embedded Objects differently based on different versions.
Further information about DSI’s document archive migration services can be found here.
© 2026 Data Strategies Interchange, LLC. - All Rights Reserved